Prompt Cache Approaches for Applications Using LLM

I work as a software architect and developer, I'm curious and I like trying new things. I like writing and helping people.
Latency and cost are obstacles for developers using language models similar to GPT. High latency can hinder the experience and significantly increase costs when scaled. The use of cache can help in these situations.
Scenario
Suppose you have created an application that uses the GPT model to obtain information, and this application makes a series of calls to the GPT model's API to get responses, with some of these questions being similar or even identical. We know that each call to the model's API incurs a cost and high latency, which can have a financial impact on the company and affect the end-user experience.
One approach that could be used to reduce cost and latency is the use of cache for prompts. After some research, I found two ways to do this: prompt and pure text result cache and semantic cache. I will detail them below.
Prompt and Result Cache
The idea of this cache is simple: basically, it goes to the cache and tries to read the similar information if it exists; if not, it goes directly to the model's API and then saves or updates the information in the cache. Below is a diagram showing the steps.
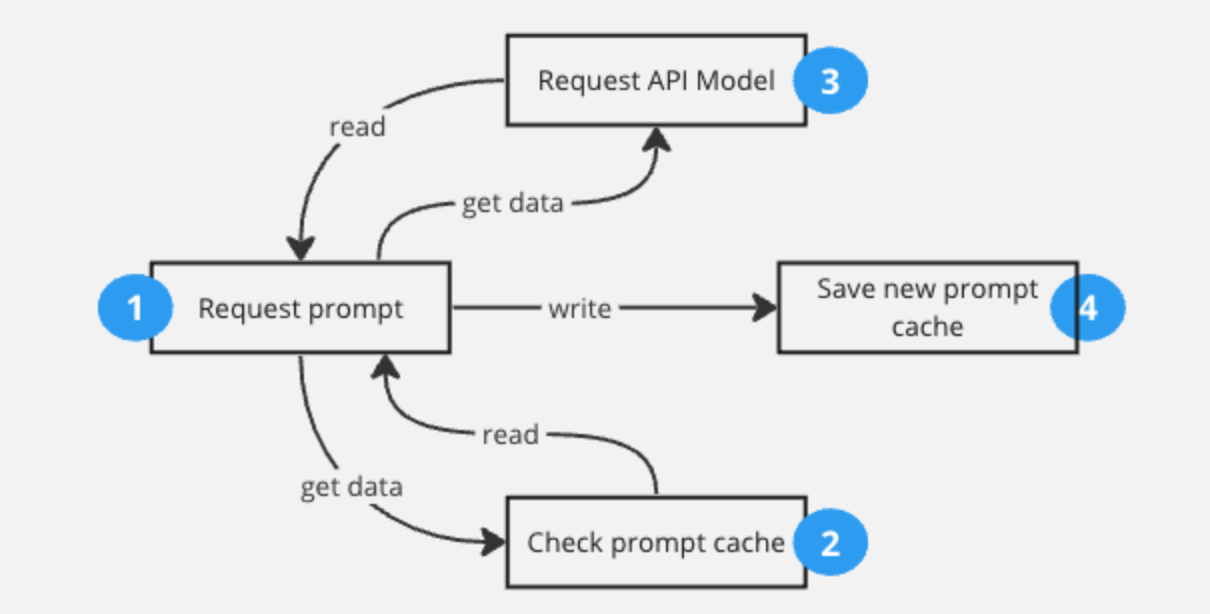
The main problem with this approach is that the prompt needs to be exactly the same to be found in the cache and return the cached result.
For this type of approach, you could use Redis, node-cache, among others. In the previous links, I left two examples using Node.js.
Semantic Cache
This type of cache uses a vector database. The idea is that it can identify similar prompts because the user might type different prompts but with similar semantics. Below is a practical example.

The approach used by Portkey employs Pinecone as a vector database. In this link, you can see some examples using Node.js for implementation.
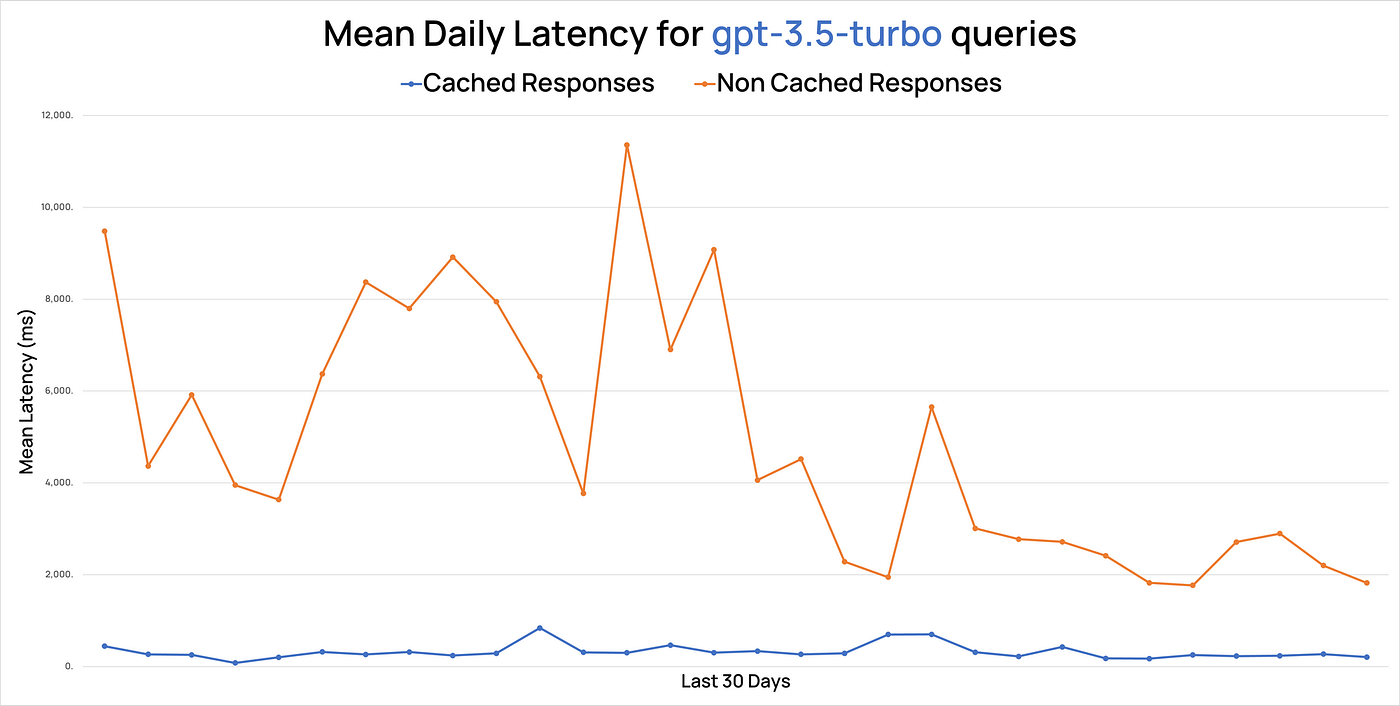
The image shows the gain from using semantic cache, resulting in a faster user experience and lower costs. It is worth noting that it does not yet have a 100% hit rate.
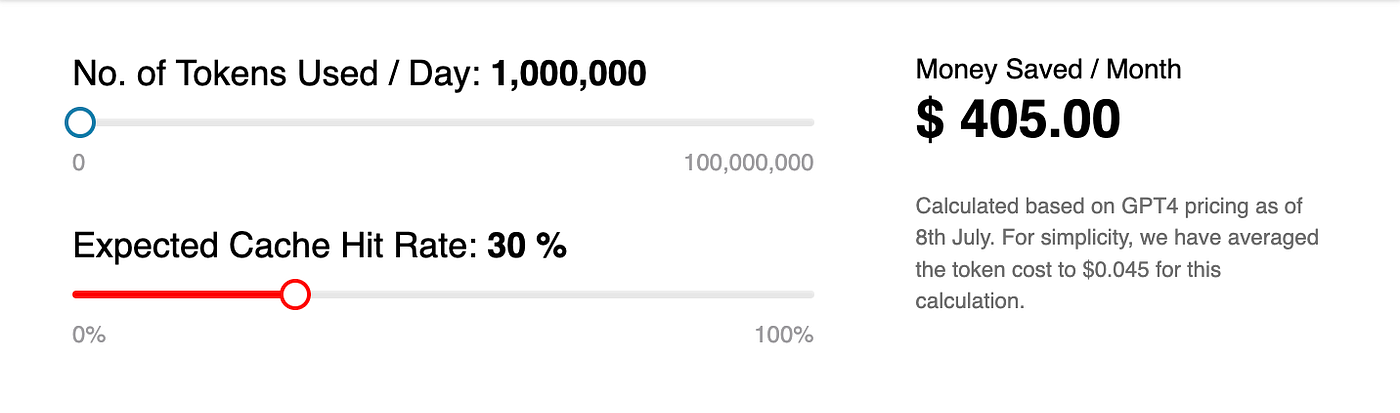
Regarding cost, we can see below in the image that for a daily token amount of 1 million and a prompt hit rate of 30%, there is a saving of $405 per month.
Incorporating caching strategies, such as prompt and result cache or semantic cache, can significantly improve the performance and cost-efficiency of applications utilizing language models like GPT. While prompt and result cache provides a straightforward approach, semantic cache offers a more advanced solution by identifying semantically similar prompts. By leveraging these techniques, developers can enhance user experience and reduce operational expenses, making the deployment of language models more sustainable and effective.
References
https://blog.portkey.ai/blog/reducing-llm-costs-and-latency-semantic-cache/



