
Building an AI Assistant with Langflow and AstraDB: From Architecture to Integration with Nocobase
AI assistant to generate insights from the data contained in system, such as Applications, API Catalog, Solution Design, and Stories.


Table of contents
- Introduction
- Architecture Overview
- Application Using Nocobase
- What are LangFlow and AstraDB?
- Installing LangFlow
- Configuring AstraDB
- Loading Data into the Vector Database
- Important Points
- Conducting Research Using a Model
- Configuring Workflow in NocoBase
- Adding the Chat Widget in NocoBase
- Testing the Chat
- Conclusion
Introduction
The objective of this article is to demonstrate the creation of an AI assistant integrating the tools Nocobase, LangFlow, and VectorDB. As a foundation, I will use the system I have been developing in Nocobase, used to manage architecture data, adding an AI assistant to generate insights from the data contained in this system, such as Applications, API Catalog, Solution Design, and Stories.
For this article, we will use the following technologies:
Nocobase, PostgreSQL, and Docker, previously configured (in this article, I will show how to install them).
LangFlow, used locally, whose installation can be found here via Docker.
Vector database, by opening an account in AstraDB, which will be the vector database used in this article.
Architecture Overview
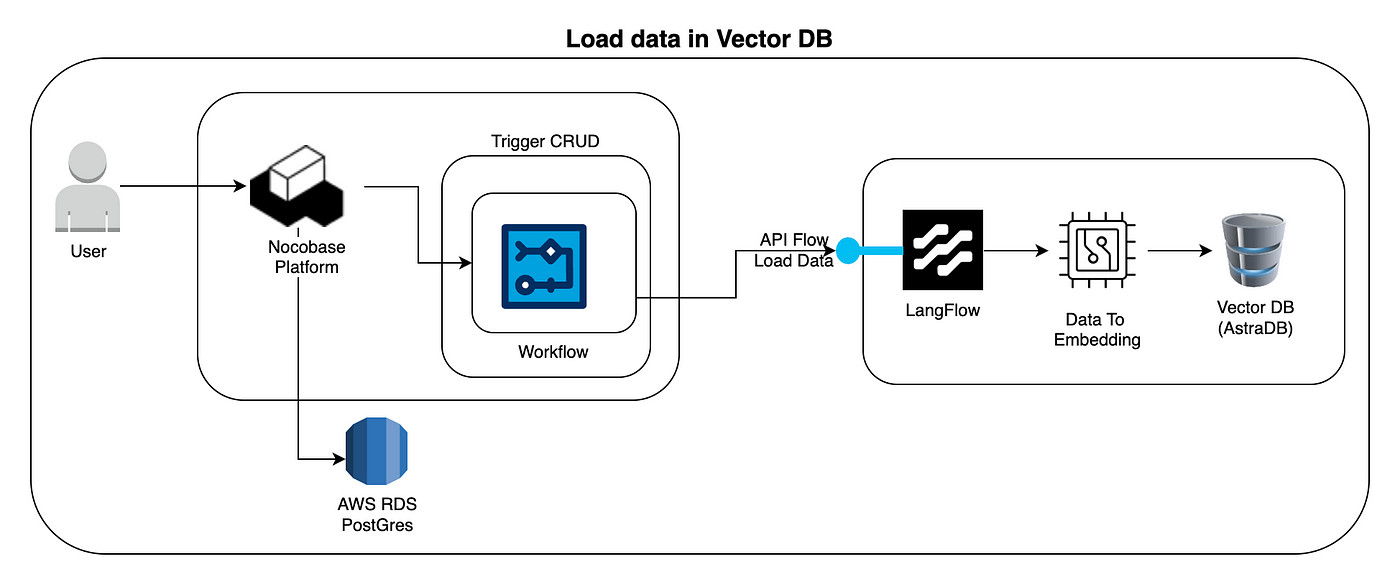
This diagram shows how new data (or updated data) is transformed into embeddings and stored in the vector database.
User → Nocobase Platform
The user interacts with the Nocobase platform (e.g., adding or updating a record in a collection).Trigger CRUD
A CRUD action (Create, Read, Update, Delete) in Nocobase triggers an event or an internal workflow.Workflow (Nocobase)
Nocobase has a workflow configured to respond to data changes. When it detects the creation or modification of a record, it initiates the next step.API Flow: Load Data
The Nocobase workflow calls an API or external service from LangFlow to send the data that will be transformed into embeddings.LangFlow — Data to Embedding
LangFlow receives the data and, using language models, converts the content into vectors (embeddings). These embeddings represent the meaning or context of the text numerically, enabling semantic searches.Vector DB (AstraDB)
The embeddings are then stored in the vector database (AstraDB), associating each embedding with the original content (e.g., a document, a record, a text).
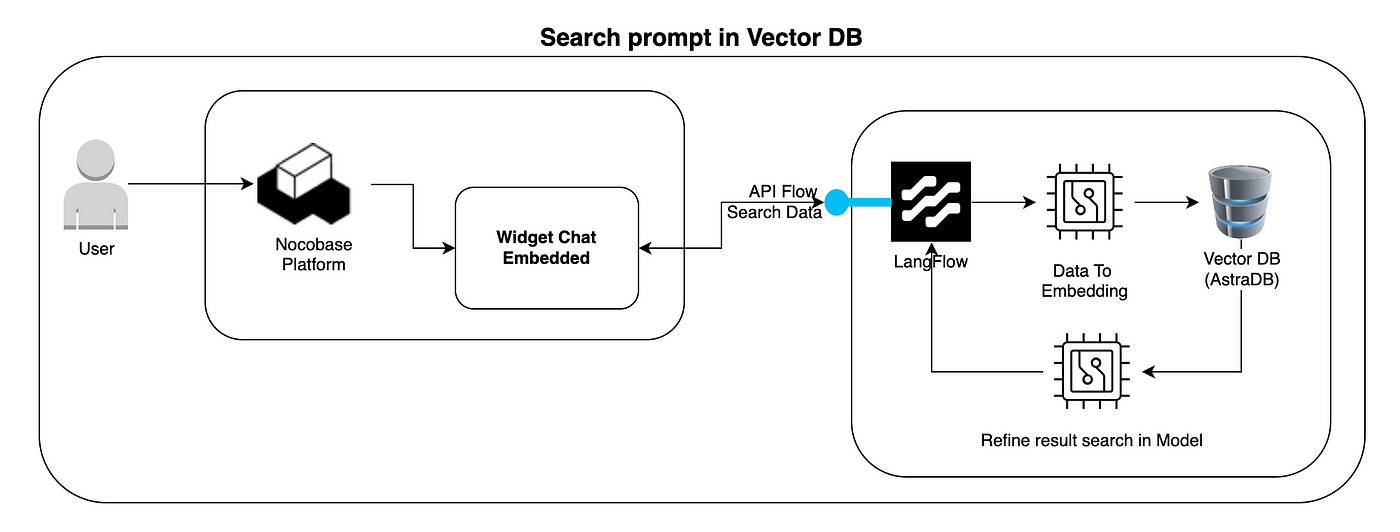
This diagram also illustrates how the user performs semantic queries on the vector database, receiving relevant results.
User → Nocobase Platform
The user interacts again with the Nocobase platform, but this time using an Embedded Chat Widget (or another search interface).Widget Chat Embedded
The user types a question or prompt. For example: "Show me information about application X." This widget sends a request to LangFlow, which processes the query.LangFlow — Data to Embedding
LangFlow converts the user's prompt into an embedding, which represents the search intent in vector format.Vector DB (AstraDB) — Similarity Search
The embedding from the prompt is used to search AstraDB for the most similar vectors (i.e., the contents that are semantically closest).Refine Result Search in Model
Based on the results returned by AstraDB, LangFlow refines the search result using OpenAI models (or another LLM).Response to User
The final result (texts, documents, or generated response) is returned to the Nocobase chat widget, displaying the response to the user.
Application Using Nocobase
For this article, I will use the same application previously created. It is an application developed to demonstrate the features of Nocobase, in which I will implement the AI assistant. Below is an image illustrating how the assistant will work.
The idea is to obtain insights about functionalities through questions. The available functionalities are: Applications, API Catalog, Solution Design, and Stories.

What are LangFlow and AstraDB?
LangFlow is an open-source tool developed by Brazilian creators, offering a graphical interface to build, visualize, and debug workflows involving language models. Based on the LangChain ecosystem, LangFlow facilitates the creation of natural language processing (NLP) pipelines and generative AI applications interactively, allowing developers to connect different components — such as API calls, text transformations, and business logic — without intensive coding.
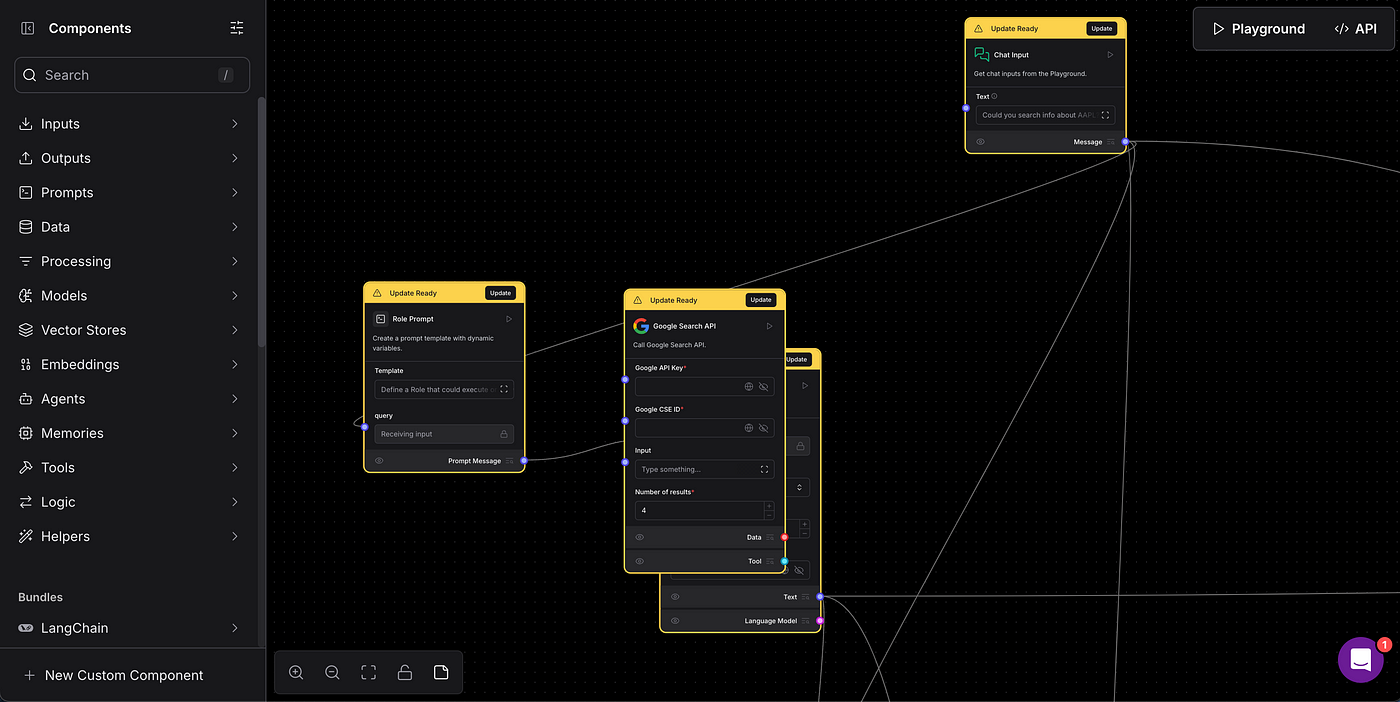
In this article, we will use AstraDB, where we will store our vectorized data. To better understand vector databases, here is an article I wrote. Also, remember that LangFlow allows switching to other vector databases.
AstraDB, originally known as a distributed database service based on Apache Cassandra, has expanded its capabilities to handle unstructured data storage and vector searches. This vector database functionality is particularly useful for machine learning applications, semantic search, recommendation systems, and high-dimensional data tasks.
Installing LangFlow
To install LangFlow via Docker, simply run the following command and then access the system at localhost:7860:
docker run -it --rm -p 7860:7860 langflowai/langflow:latest
Configuring AstraDB
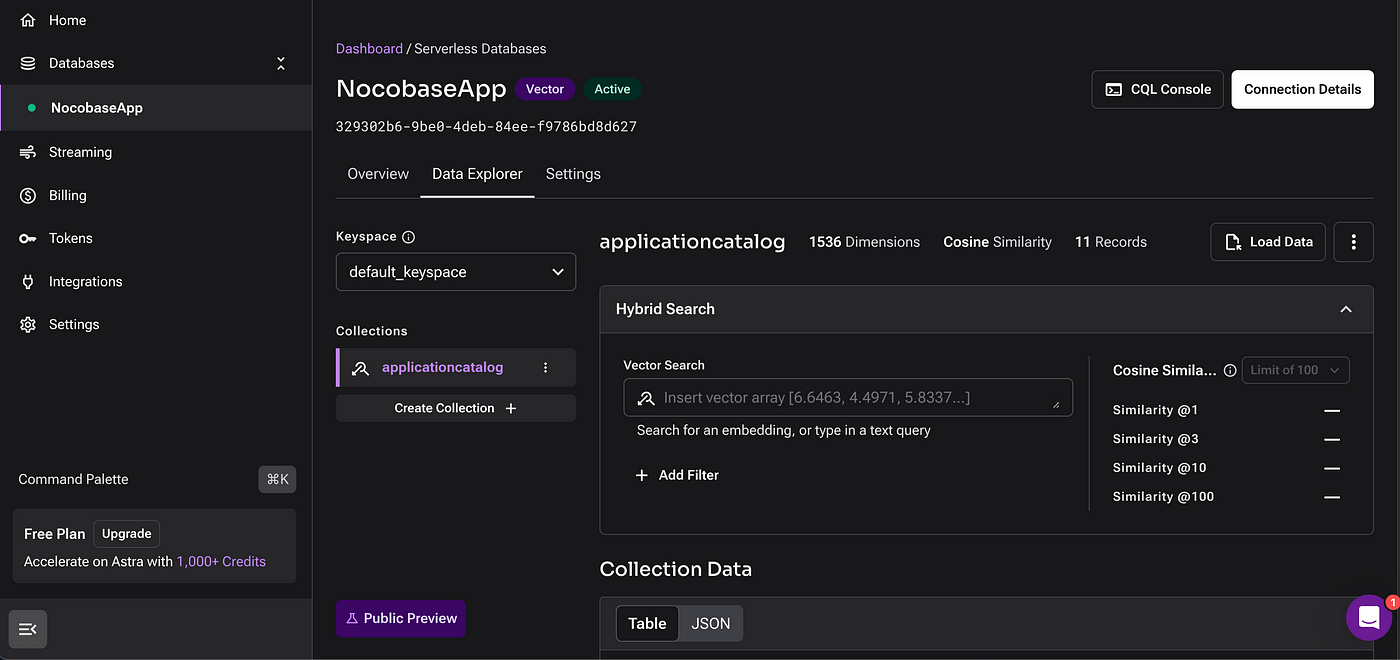
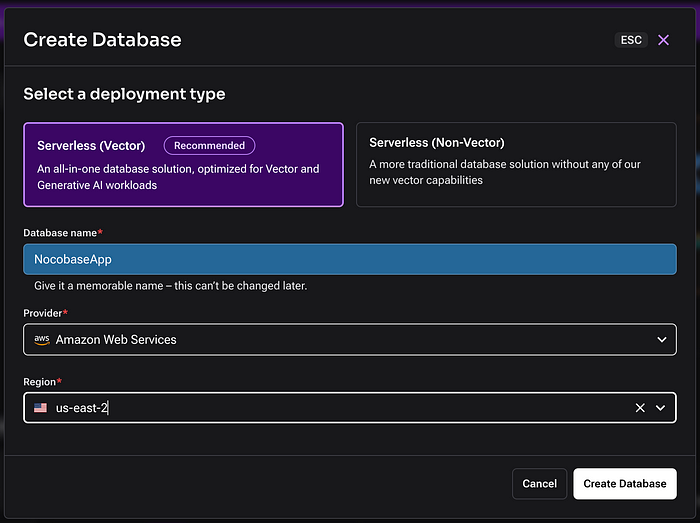
After creating an account on AstraDB, you can set up the database and collection with the data, as shown below.
The process is quite simple:
Choose a provider
Select a region
Create the database
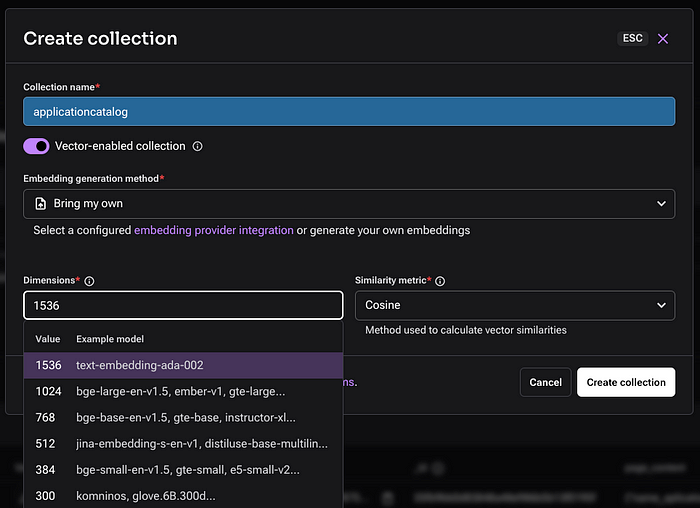
For the collection, since it stores vectorized data, it is crucial to configure the Embedding feature, which corresponds to the LLM model responsible for vectorizing the data.
There are several models for embedding generation, such as those from OpenAI, Nvidia, and Google. In this case, we will use the text-embedding-ada-002 model for data conversion.
Loading Data into the Vector Database
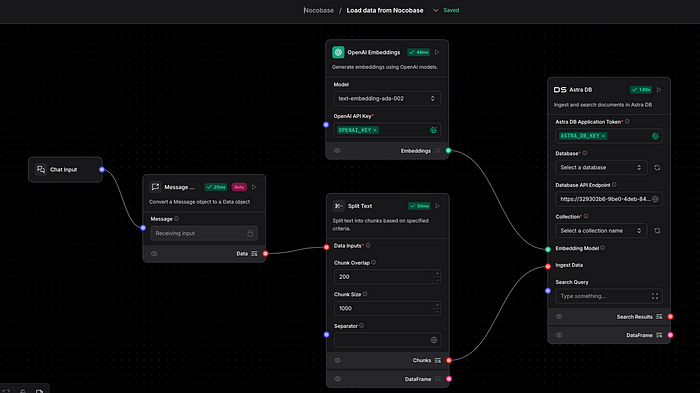
This step feeds our vector database with the data to be searched.
The LangFlow workflow receives the data via a URL.
Processes the text
Converts it to vector format using text-embedding-ada-002
Stores it in AstraDB in the configured collection.
Important Points
It is necessary to define the AstraDB Token in the component responsible for the database connection. To generate the token, simply access the collection in AstraDB and click Generate Token. The image below shows the screen with the corresponding button.
Database Overview: The source file can be found in my repository.
For the model we are using, it is necessary to add credits to access the OpenAI API. The following documentation explains how to complete this process. After adding credits, you must generate a token and define it in the component responsible for embedding generation. Here is a link with instructions on this process. Remember that there are various models available for generating embeddings.
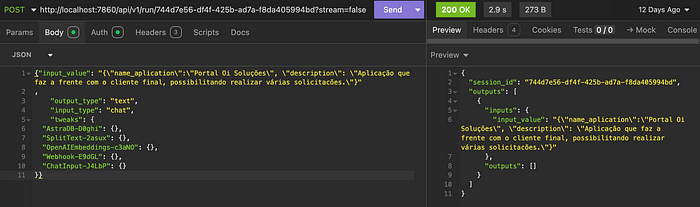
To test, simply use Postman, calling the URL that can be obtained from API > cURL in LangFlow. Below is an example of a request using Postman.
Conducting Research Using a Model
This step is responsible for retrieving data from the vector database and refining it through RAG (Retrieval-Augmented Generation).
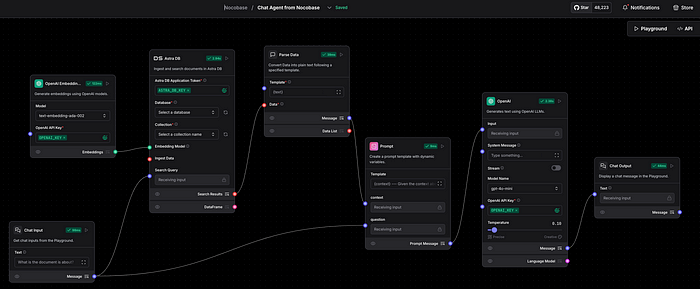
At this stage, it is also necessary to define the OpenAI and AstraDB tokens in their respective components. The source file can be found in my repository.
To test it, simply use the Chat, available inside LangFlow in the Playground tab.
Configuring Workflow in NocoBase
In this step, we will create triggers in our application to send the data that needs to be vectorized. In other words, whenever new data is inserted, it will be sent to the LangFlow API for processing.
To achieve this, we will use the Workflow feature of NocoBase. For more details on workflows, access the link.

We will create a workflow to send data from our application's collection to the vectorized collection.
Steps:
Create a new workflow as shown below, Collection Event.

Define the Trigger as an insertion in the Application collection, as shown below.

Create a new Request node to send the application's data for vectorization. In this article, we will use Title and Description as examples, but any information can be sent according to business rules.

The Notification step is optional and does not need to be executed.
Adding the Chat Widget in NocoBase
First, access LangFlow and copy the Chat Widget code from the API option, as shown in the image below.
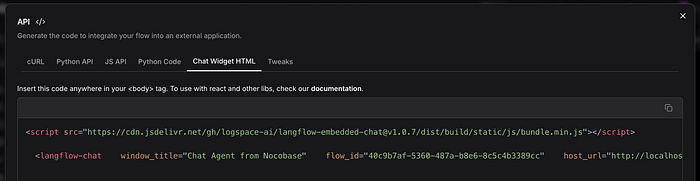
In the second step, simply create a page and add an iframe component. For more details about this component, you can check the link.
Where:
Mode: HTML
HTML: The code below, replacing the flow_id and host_url according to the values from LangFlow.

Testing the Chat
Now, let's go back to the created menu, test our Assistant, and check the response, as shown in the example below.

Conclusion
In this article, we demonstrated the creation of an AI assistant integrated with NocoBase, LangFlow, and AstraDB, enabling vectorization and intelligent data retrieval.
With this approach, we were able to implement an assistant capable of generating valuable insights from registered data, using RAG (Retrieval-Augmented Generation) techniques to refine search results.
This is just the beginning of what this architecture can offer. With small adaptations, it is possible to expand functionalities, integrate new AI models, and enhance the user experience. 🚀